Pandas is a highly popular, open-source data manipulation and analysis library for Python, designed to make working with structured data fast, easy, and more efficient. Originally developed by Wes McKinney in 2008, Pandas has become an essential tool for data scientists, analysts, and engineers due to its rich set of features that facilitate data processing.
Key Features of Pandas:
- Data Structures:
- Series: A one-dimensional, labeled array that can hold any data type, like integers, strings, or floating-point numbers. It’s often used for time series data or simple lists of values.
- DataFrame: A two-dimensional, labeled data structure similar to a table in relational databases or an Excel spreadsheet, containing rows and columns. DataFrames are the most commonly used Pandas object for analyzing datasets.
- Data Handling and Cleaning:
- Pandas offers numerous functions for data cleaning like handling missing values, removing duplicates, and converting data types, which are critical for preparing data for analysis.
- It allows for easy filtering and subsetting of data, whether you’re working with rows or columns.
- Data Transformation:
- Pandas supports reshaping data through operations like pivoting, stacking, melting, and more. These transformations are key for preparing datasets for specific analysis tasks.
- It also supports vectorized operations, which means applying functions across entire columns or rows without needing to write loops, making data operations highly efficient.
- Reading and Writing Data:
- Pandas can read data from a wide variety of file formats like CSV, Excel spreadsheets, SQL databases, JSON, HTML tables, and more. This makes it extremely flexible for integrating with different data sources.
- Similarly, it can write data back to these formats, which is helpful when you need to store or share the output of your analysis.
- Handling Missing Data:
- Pandas provides tools to detect, replace, or remove missing data (NaN values), ensuring that analyses are performed on complete datasets or are resilient to missing values.
- Data Aggregation and Grouping:
- Pandas has powerful methods for grouping data (
groupby()), enabling calculations like sums, averages, or custom aggregations across different subsets of a dataset. - The
groupby()function is particularly useful when dealing with grouped operations such as calculating the total revenue for each month or analyzing trends across categories.
- Pandas has powerful methods for grouping data (
- Data Merging and Joining:
- Pandas makes it easy to merge or join datasets, similar to SQL joins, with functions like
merge()andconcat(). These capabilities allow you to bring together data from different sources seamlessly.
- Pandas makes it easy to merge or join datasets, similar to SQL joins, with functions like
- Time Series Functionality:
- Pandas has robust support for time series data, including functions for resampling, frequency conversion, and rolling statistics, making it suitable for financial analysis, sensor data, or any time-stamped information.
- Indexing and Selection:
- The library provides advanced indexing capabilities, which make selecting data more intuitive. With
loc[]andiloc[], you can select rows and columns based on labels or position. - This feature allows users to manipulate their data flexibly, making it easy to slice and dice large datasets.
- The library provides advanced indexing capabilities, which make selecting data more intuitive. With
- Visualization Integration:
- Pandas works well with visualization libraries like Matplotlib or Seaborn for generating plots and graphs, helping to make insights more comprehensible. It has built-in visualization functions (
.plot()) to quickly generate charts directly from DataFrames.
- Pandas works well with visualization libraries like Matplotlib or Seaborn for generating plots and graphs, helping to make insights more comprehensible. It has built-in visualization functions (
- Performance:
- While Python is an interpreted language, Pandas leverages vectorized operations using NumPy, which significantly boosts performance and allows for faster data processing when working with large datasets.
- Real-World Applications:
- Data Analysis: Pandas is widely used to perform exploratory data analysis (EDA) and statistical analysis.
- Data Cleaning: Cleaning and transforming raw data for further analysis.
- Machine Learning: Often used to prepare data for machine learning models by cleaning, transforming, and engineering features.
Advantages of Pandas:
- User-Friendly: It provides an easy-to-understand API that allows for rapid data analysis, even for users who are not experts in programming.
- Open Source: It’s free to use, with an active community that frequently contributes to its development.
- Integration: Pandas integrates seamlessly with other libraries like SciPy, Scikit-Learn, and Statsmodels, making it an essential part of the data science toolkit.
Limitations of Pandas:
- Memory Intensive: Pandas is not always efficient with very large datasets as it stores data in memory. For extremely large datasets, tools like Dask or PySpark might be more suitable.
- Learning Curve: For beginners, some aspects like multi-indexing can be difficult to grasp initially.
Pandas is a cornerstone of the Python data ecosystem, providing a solid framework for data handling, analysis, and preprocessing. Its ability to seamlessly work with a variety of data formats, combined with the powerful tools it offers for cleaning and transforming data, makes it indispensable for data-driven projects in fields ranging from finance and economics to healthcare and machine learning.
Step 1: Create an Instance
First, create a server instance running Ubuntu 24.04.
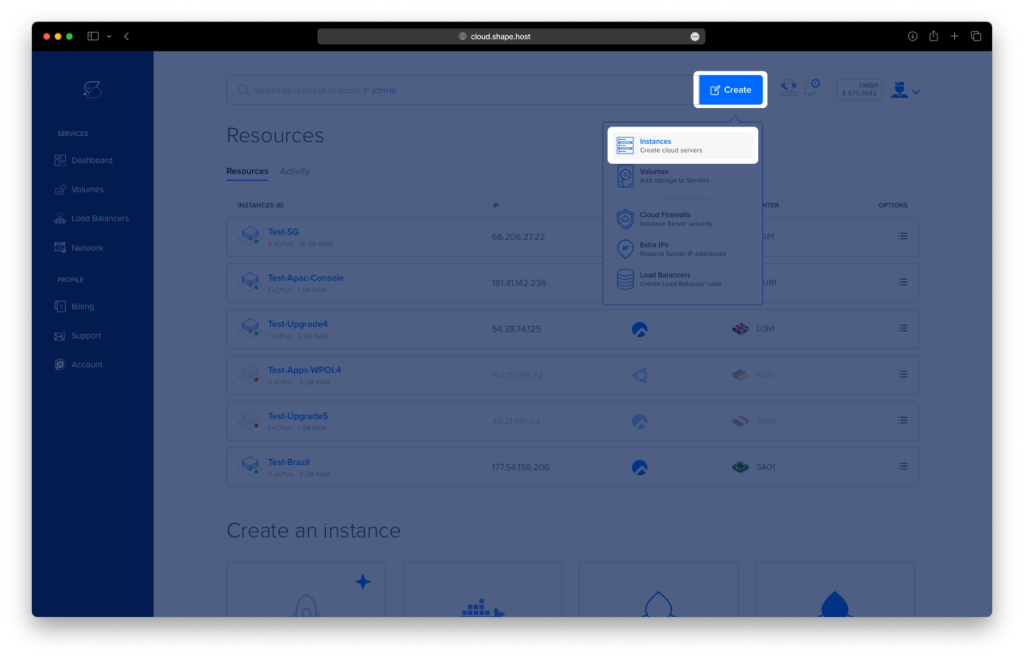
- Access the Dashboard: Log in to your Shape.Host account and navigate to your Dashboard.
- Click Create: Click on the “Create” button located in the top-right corner.
- Select Instances: From the dropdown menu, choose “Instances” to begin creating a new cloud server.
- Select Location: Choose a data center location for your instance closest to your target audience for optimal performance.
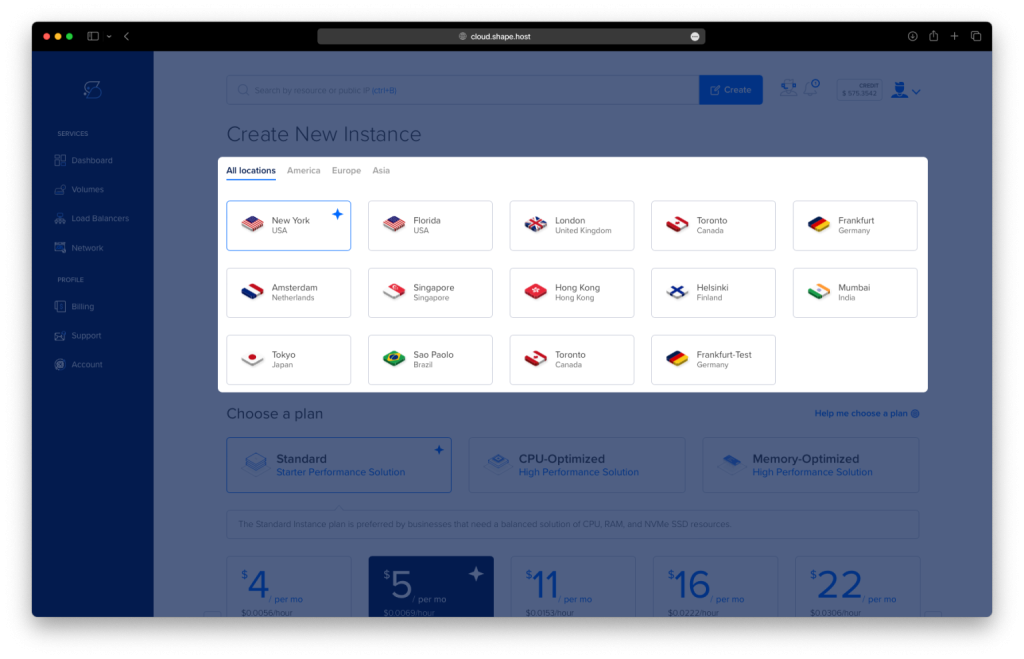
- Choose a Plan: Scroll through the available pricing plans. Select a plan based on your project requirements, such as Standard, CPU-Optimized, or Memory-Optimized.
- Choose an Image: Select Ubuntu 24.04 as the operating system for your instance.
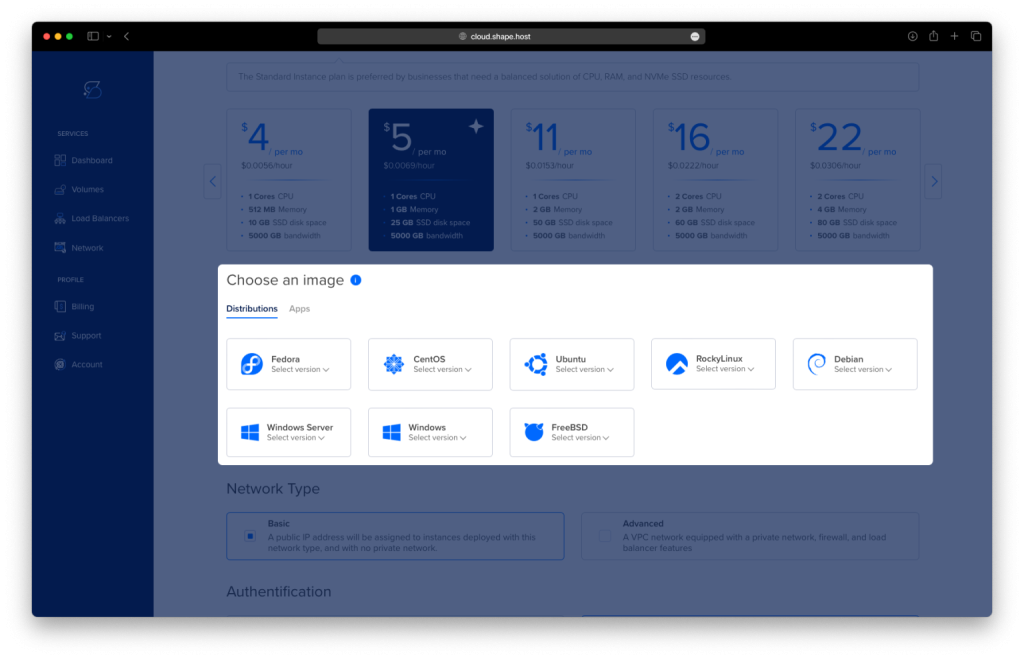
- Authentication and Finalize: Choose your authentication method, either via SSH keys or password. Once done, click Create Instance to launch your server.
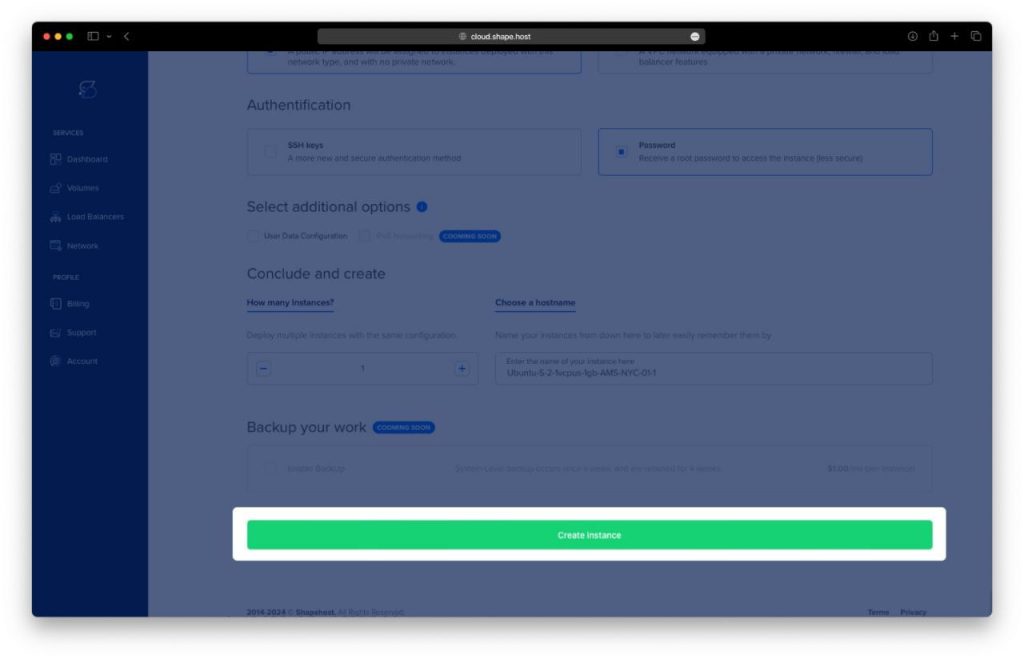
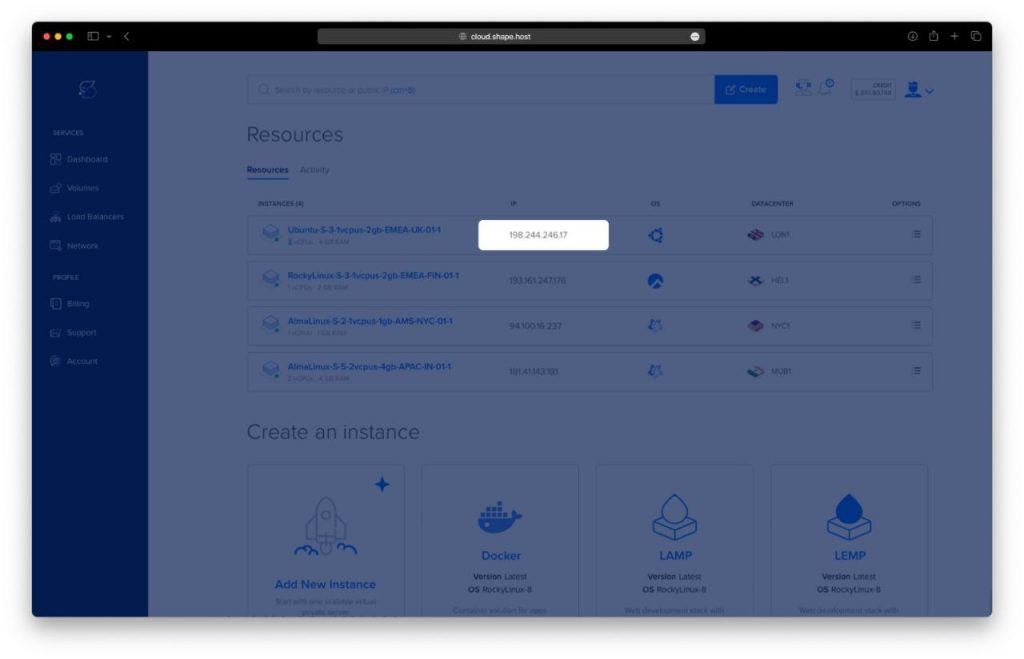
- Obtain IP Address
- Once your instance is created, return to the dashboard.
- Find your instance’s IP address under the Resources section and use it to access your server.
Step 2: Connect to Your Instance
Once your server is running, connect to it via SSH:
- Get the Instance IP: After creating your instance, find the public IP address in the Shape.Host dashboard under Resources.
- Open SSH Client: Use an SSH client like Terminal (Linux/macOS) or PuTTY (Windows).
- SSH into the Instance: Use the following command to connect to your server:
ssh root@<your-instance-ip>Replace<your-instance-ip>with your server’s actual IP address. - Enter the Password: Enter the root password or use your SSH key to complete the connection.
Step 3: Update and Install Python3 and Pip
First, update your package index to ensure you have the latest packages:
apt update && apt upgrade -y
Next, install Python3 and Pip:
apt install python3 python3-pip
Step 4: Install Pandas Globally
To install Pandas globally on your server, run:
apt install python3-pandas
To verify the installation and check the installed version, use the following command:
python3 -c "import pandas as pd; print(pd.__version__)"
Step 5: Install Pandas in a Virtual Environment
If you prefer to work in a virtual environment, follow these steps:
Step 5.1: Install Virtualenv
Install the virtualenv package:
apt install virtualenv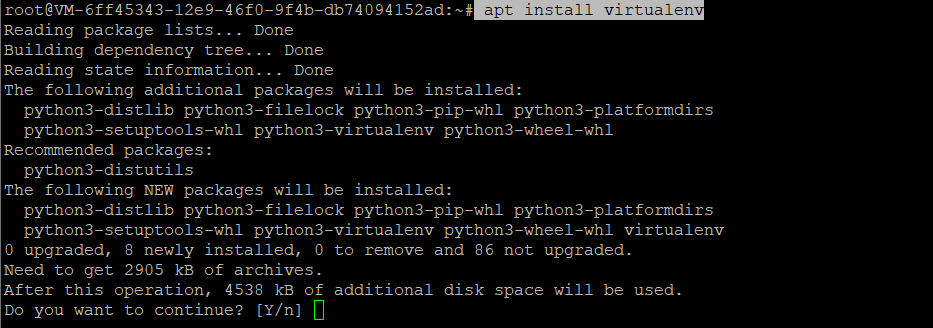
Step 5.2: Create a Virtual Environment
Create a virtual environment for your project:
virtualenv my_project_env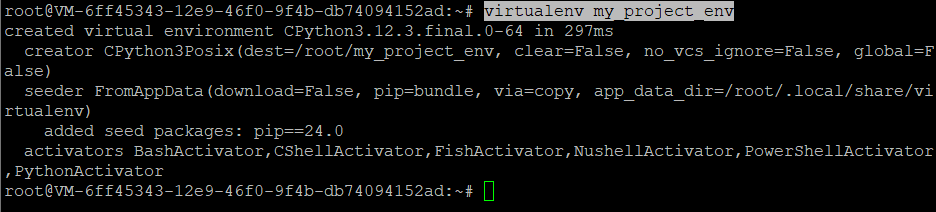
Activate the virtual environment:
source my_project_env/bin/activate
Step 5.3: Install Pandas in the Virtual Environment
Once the virtual environment is active, install Pandas using pip:
pip3 install pandas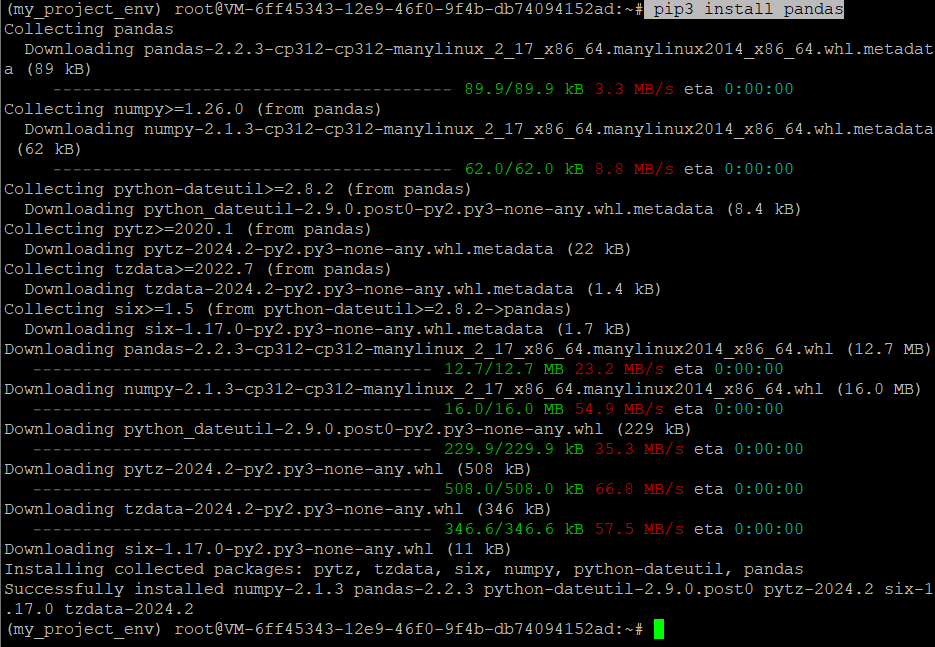
To verify the installation:
pythonThen type:
import pandas as pd
print(pd.__version__)
Exit the Python shell:
exit()Step 5.4: Deactivate the Virtual Environment
To deactivate the virtual environment, use:
deactivate
If you’re looking for reliable hosting solutions to run your data analysis projects, consider Shape.Host Cloud VPS. With Shape.Host, you get flexible, scalable, and robust cloud infrastructure tailored for Python development and other data-driven tasks. Get started today with a powerful VPS that meets your project needs.